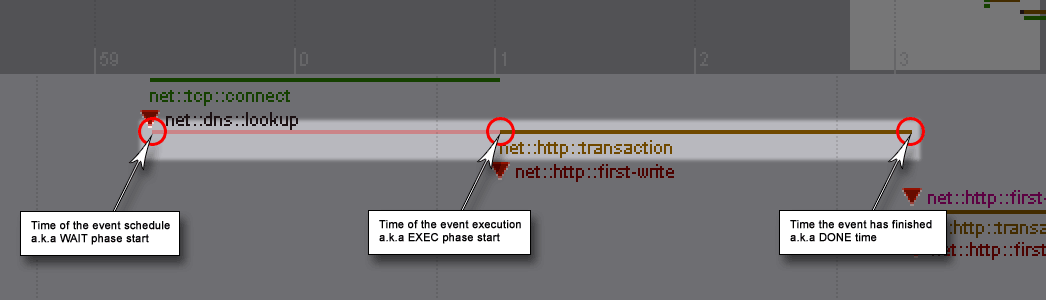
Yes, it's on! After a little bit more than a year of a development by me and Michal Novotný all bugs we could find in our labs, offices and homes were fixed. The new cache back-end is now enabled on Firefox Nightly builds as of version 32 and should stay like that.
The old cache data are for now left on disk but we have handles to remove them automatically from users' machines to not waste space since it's now just a dead data. This will happen after we confirm the new cache sticks on Nightlies.
The new HTTP cache back end has many improvements like request prioritization optimized for first-paint time, ahead of read data preloading to speed up large content load, delayed writes to not block first paint time, pool of most recently used response headers to allow 0ms decisions on reuse or re-validation of a cached payload, 0ms miss-time look-up via an index, smarter eviction policies using frecency algorithm, resilience to crashes and zero main thread hangs or jank. Also it eats less memory, but this may be subject to change based on my manual measurements with my favorite microSD card which shows that keeping at least data of html, css and js files critical for rendering in memory may be wise. More research to come.
Thanks to everyone helping with this effort. Namely Joel Maher and Avi Halachmi for helping to chase down Talos regressions and JW Wang for helping to find cause of one particular hard to analyze test failure spike. And also all early adopters who helped to find and fix bugs. Thanks!
New preferences to play with:
browser.cache.disk.metadata_memory_limit- Number of kBs we reserve for keeping recently loaded cache entries metadata (i.e. response headers etc.) for quick access and re-validation or reuse decisions. By default this is at 250kB.
browser.cache.disk.preload_chunk_count- Number of data chunks we always preload ahead of read to speed up load of larger content like images. Currently size of one chunk is 256kB, and by default we preload 4 chunks - i.e. 1MB of data in advance.
Load times compare:
Since these tests are pretty time consuming and usually not very precise, I was only testing with page 2 of my blog that links some 460 images. Media storage devices available were: internal SSD, an SDHC card and a very slow microSD via a USB reader on a Windows 7 box.
[ complete page load time / first paint time ]
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 7.4s / 450ms | 880ms / 440ms | 510ms / 355ms | 5s / 430ms |
| cache v2 | 6.4s / 445ms | 610ms / 470ms | 470ms / 360ms | 5s / 440ms |
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 7.4s / 635ms | 760ms / 480ms | 545ms / 365ms | 5s / 430ms |
| cache v2 | 6.4s / 485ms | 1.3s / 450ms | 530ms / 400ms* | 5.1s / 460ms* |
Edit: I found one more place to optimize - preload of data sooner in case an entry has already been used during the browser session (bug 1013587). We are winning around 100ms for both first paint and load times! Also stddev of first-paint time is smaller (36) than before (80). I have also measured more precisely the load time for non-patched cache v2 code. It's actually better.
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 13s / 1.4s | 1.1s / 540ms | 560ms / 440ms | 5.1s / 430ms |
| cache v2 | 6.4s / 450ms | 1.7s / 450ms | 710ms / 540ms* | 5.4s / 470ms* |
| cache v2 (with bug 1013587) | - | - | 615ms / 455ms* | - |
* We are not keeping any data in memory (bug 975367 and 986179) what seems to be too restrictive. Some data memory caching will be needed.
"Jankiness" compare:
The way I have measured browser UI jank (those hangs when everything is frozen) was very simple: summing every stuck of the browser UI, taking more then 100ms, between pressing enter and end of the page load.
[ time of all UI thread events running for more then 100ms each during the page load ]
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 0ms | 600ms | 0ms | 0ms |
| cache v2 | 0ms | 0ms | 0ms | 0ms |
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 600ms | 600ms | 0ms | 0ms |
| cache v2 | 0ms | 0ms | 0ms | 0ms |
| Cache version | First visit | Cold go to 1) | Warm go to 2) | Reload |
|---|---|---|---|---|
| cache v1 | 2500ms | 740ms | 0ms | 0ms |
| cache v2 | 0ms | 0ms | 0ms | 0ms |
All load time values are medians, jank values averages, from at least 3 runs without extremes in attempt to lower the noise.
1) Open a new tab and navigate to a page right after the Firefox start.
2) Open a new tab and navigate to a page that has already been visited during the browser session.