Did you ever dream of debugging Firefox in Visual Studio with all its child processes attached automatically? And also when being started externally from a test suit like mochitest or browsertest? Tired of finding the right pid and time to attach manually? Here is the solution for you!
Combination of the following two extensions to Visual Studio Community 2015 will do the trick:
- Spawned Process Catcher X – attaches automatically to all child processes the debugee (and its children) spawns
- Entrian Attach – attaches the IDE automatically to an instance of a process spawned FROM ANYWHERE, e.g. when running tests via
machwhere Firefox is started by a python script – yes, magic happens ;)
Spawned Process Catcher X works automatically after installation without a need for any configuration.
Entrian Attach is easy to configure: In the IDE, in the main menu go to TOOLS/Entrian Attach: Configuration…, you’ll get the following window:
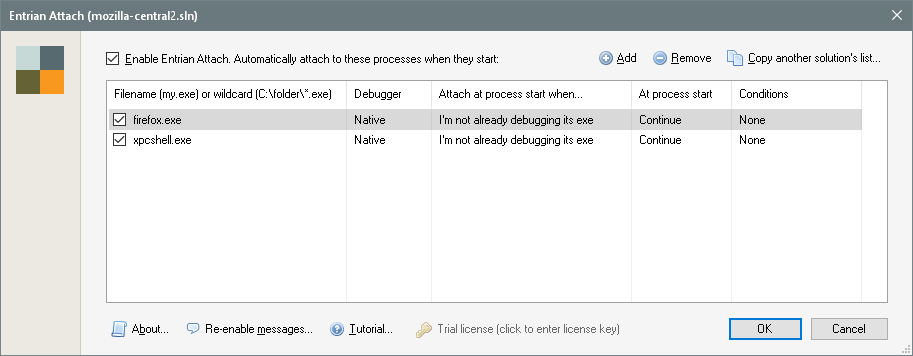
UPDATE: It’s important to enter the full path for the executable. The Windows API for capturing process spawning is stupid – it only takes name of an executable, not a full path or wildchars. Hence you can only specify names of executable files you want Entrian Attach to automatically attach to. Obviously, when Visual Studio is running with Entrian Attach enabled and you start your regular browser, it will attach too. I’ve added a toolbar button EntrianAttachEnableDisable to the standard toolbar for a quick switch and status visibility.
Other important option is to set Attach at process start when to “I’m not already debugging its exe”. Otherwise, when firefox.exe is started externally, a shim process is inserted between the parent and a child process which breaks our security and other checks for expected pid == actual pid. You would just end up with a MOZ_CRASH.
Note that the extension configuration and the on/off switch are per-solution.
Entrian Attach developer is very responsive. We’ve already cooked the “When I’m not already debugging its exe” option to allow child process attaching without the inserted shim process, took just few days to release a fixed version.
Entrian Attach is a shareware with 10-day trial. Then a single developer license is for $29. There are volume discounts available. Hence, since this is so super-useful, Mozilla could consider buying a multi-license. Anyway, I believe it’s money very well spent!
